Kapitel 2
Karakteristik af programudviklingsmiljø
Dette kapitels karakteristik af programudviklingsmiljøet baserer sig dels på en række trykte kilder, dels på egne erfaringer. Vi opstiller en taksonomi, som baserer sig på den traditionelle opfattelse af de centrale elementer i programudviklingsmiljøet; men hvad vi beskriver som væsentligt og mindre væsentligt for de enkelte elementer beror for langt størstepartens vedkommende på vores egne erfaringer. Der bliver således tale om en syntese af teori og praksis.
Det har været vigtigt for os, at producere en nuanceret taksonomi, fordi vi ikke tror på at man, i hvert fald inden for dette område, kan lave en anvendelig taksonomi, hvor resultatet af anvendelsen af taksonomien på et givet produkt er et tal eller en karakter, således at man meget nemt kan lave en indbyrdes rangordning af produkter.
2.1 Værktøjer generelt - programmeringssprogets rolle
I de traditionelle fremstillinger af programmeringsomgivelser, f.eks. [Nørmark89] tilstræber man at adskille vurderinger af programmeringsomgivelserne og vurderinger af programmeringssproget. Det kan der være flere årsager til.
En af årsagerne kunne være, at det er der tradition for - en anden årsag kunne være, at man har den opfattelse, at den optimale programmeringsomgivelse skal kunne håndtere et hvilket som helst af de generelle sprog, hvorved vurderingen af sproget naturligt henhører til en anden sammenhæng.
Vi er meget enige i den sidste antagelse; men må dog samtidig erkende, at de fleste moderne omgivelser er udviklet med et bestemt programmeringssprog i tankerne og deres udformning er derfor påvirket heraf.
I den følgende beskrivelse af værktøjerne, vil vi tilstræbe en så sproguafhængig linje som mulig; men vi er naturligvis påvirket af de miljøer, vi specifikt har arbejdet med, og derfor vil fremstillingen næppe kunne betegnes som fuldt dækkende. Specifikt i vores fremstilling af compilere læner vi os en hel del op ad [Aho86], hvis principper heller ikke nødvendigvis dækker området fuldt ud; men fremstillingen er så bredt anerkendt, at vi føler os i trygge hænder.
Et programudviklingsmiljø kan ifølge Nørmark defineres som en integreret samling af programmeringsværktøj.
Et programmeringsværktøj kan defineres som en stump software eller hardware, der kan understøtte programmøren i udførelsen af en veldefineret opgave i programudviklingsprocessen. [Nørmark89]
I den ovenstående definition er der tre centrale begreber: værktøj, integration og programudviklingsproces. Når man skal karakterisere et givet programudviklingsmiljø, er det derfor nødvendigt, at man som minimum beskriver det konkrete programudviklingsmiljø i forhold til disse tre begreber.
Det har ført til den naturlige opdeling af resten af dette kapitel i tre afsnit, hvor vi henholdsvis vil beskrive værktøjerne, integrationen og systemudviklingsprocessen. At vi kalder det tredie afsnit for systemudviklingsprocessen i stedet for programudviklingsprocessen hænger sammen med, at vi som nævnt tidligere vil argumentere for, at det er nødvendigt at inddrage hele systemudviklingsprocessen for at forstå programudviklingsprocessen.
Editering
kan defineres som indtastning og redigering af kildetekst.Kildetekst kan defineres som den repræsentation, et program skal være på, når det skal være input til oversætteren eller fortolkeren. Den primære repræsentation for kildeteksten er almindelig lineær tekst; men andre former for repræsentation kan forekomme - ikke mindst i forbindelse med de visuelle udviklingsmiljøer.
Editoren er det værktøj, som programmøren bruger, når programmets kildetekst skal editeres. Den følgende beskrivelse af editorer er primært baseret på Nørmark. [Nørmark89]
En editor kan i sin simpleste form være en generel editor - et program til indtastning og editering af tekst. Et sådant generelt program har ikke nogen relation til det programmeringssprog, som det indtastede program er skrevet i, og den generelle editor er derfor ikke til nogen hjælp i forbindelse med fejlfinding i programmet.
Den generelle editor er et meget fleksibelt værktøj, som kan bruges til mange andre ting end editering af programmers kildetekst. Editorer kan f.eks. også bruges til læsning af tekstfiler.
Eksempler på generelle editorer er
De generelle editorer er mest udbredte i relation til det traditionelle udviklingsmiljø, som beskrevet i afsnit 1.2.2.
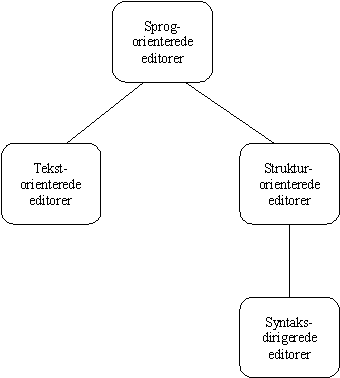
Figur 2-1
. Sammenhængen mellem forskellige typer af editorer.I de fleste udviklingsmiljøer møder man som regel de sprog-orienterede editorer. Disse editorer er specielt udformet med henblik på editering af kildetekst - ofte skræddersyet til et bestemt sprog eller til et bestemt udviklingsmiljø.
Nørmark skelner indenfor de sprog-orienterede editorer mellem tekst-orienterede, struktur-orienterede og syntaks-dirigerede editorer. Sammenhængen mellem de forskellige typer fremgår af figur 2-1. Figuren stammer fra [Nørmark89].
Tekst-orienterede editorer har fået deres betegnelse, fordi lineær tekst i form af en sekvens af tegn er den mest udbredte metode til repræsentation af programmer i forbindelse med editering. Ofte tilbyder editoren dog en eller flere af følgende faciliteter som hjælp i forbindelse med editeringen:
Nørmark omtaler editoren Emacs som et eksempel på en generel editor, der kan tilpasses til forskellige programmeringssprog, så den på den måde bliver en sprog-orienteret tekst editor.
Muligheden for tilpasning af editoren er en meget udbredt facilitet, der giver brugerne (programmørerne) gode muligheder for at tilpasse editorens funktionalitet, så den er afstemt med det aktuelle behov.
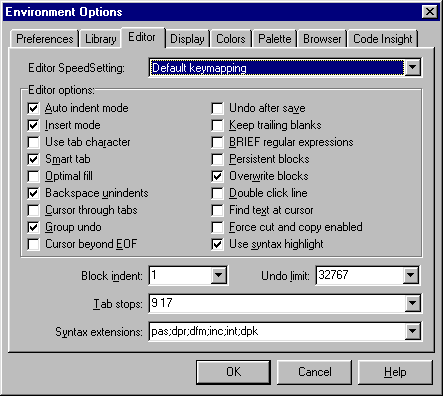
Figur 2-2
. Eksempel på mulighederne for tilpasning af editoren i Delphi 3.Figur 2-2 viser det skærmbillede fra udviklingsmiljøet Delphi 3, der giver mulighed for at tilpasse editoren. En af de muligheder, der tilbydes, er en service overfor de programmører, der har taget hele turen med fra Turbo Pascal, idet man kan få editoren til at opføre sig som den editor, der var et integreret værktøj i den første Turbo Pascal, hvis man altså skulle ønske det.
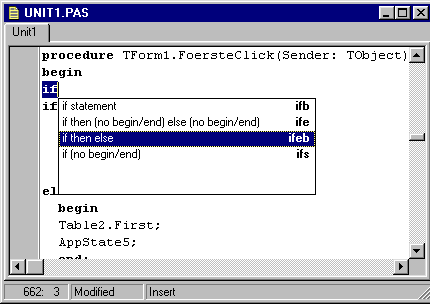
Figur 2-3
. Eksempel på aktivering af syntaktisk skabelon i Delphi 3 editoren.Figur 2-3 og figur 2-4 viser to stadier i et eksempel på understøttelse af syntaktiske skabeloner, ligeledes hentet fra Delphi 3. I figur 2-3 er aktiveringen af den syntaktiske skabelon netop foretaget. Det foregår ved, at man taster ctrl-j. Hvis det - som i dette tilfælde - gøres lige efter indtastningen af ordet if, åbnes et vindue med de skabeloner, som er relevante for if. I eksemplet har vi allerede udpeget den skabelon, der hedder if-then-else. Resultatet af valget fremgår af figur 2-4. Man ser, at de nøgleord, der kræves af sprogets syntaks, allerede er sat ind i programmet.
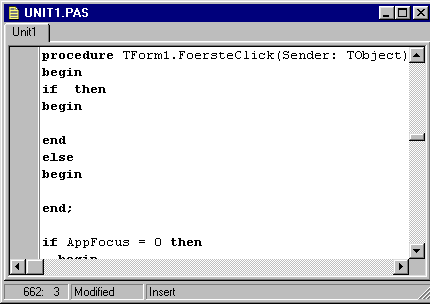
Figur 2-4
. Eksempel på resultatet af aktivering af en syntaktisk skabelon i Delphi 3 editoren.En struktur-orienteret editor er ifølge Nørmark et værktøj, som understøtter interaktiv editering af en eller anden datastruktur, som i mange tilfælde vil være hierarkisk [Nørmark89]. Det lykkes ikke Nørmark at argumentere overbevisende for, hvordan en struktur-orienteret editor adskiller sig fra en tekst-orienteret. Hvis definitionen er "en eller anden" datastruktur, må den lineære struktur i den almindelige kildetekst jo også være omfattet.
Nørmark vælger at se bort fra de lineære strukturer, og begrænser derved definitionen "en eller anden" datastruktur til at gælde ikke-lineære strukturer. Nørmark omtaler især de hierarkiske strukturer (træer).
Siden Nørmarks skrift er udkommet må man sige, at der er sket meget på dette område. I mange sammenhænge er man afhængig af en editor, der kan håndtere både hierarkiske strukturer og netværksstrukturer (grafer).
Det gælder f.eks. i forbindelse med opbygning af multimedie applikationer og hypertekst. Som eksempel på en struktur-editor har vi valgt at bruge MicroSofts FrontPage, som er et avanceret værktøj til opbygning af hjemmesider på World Wide Web.
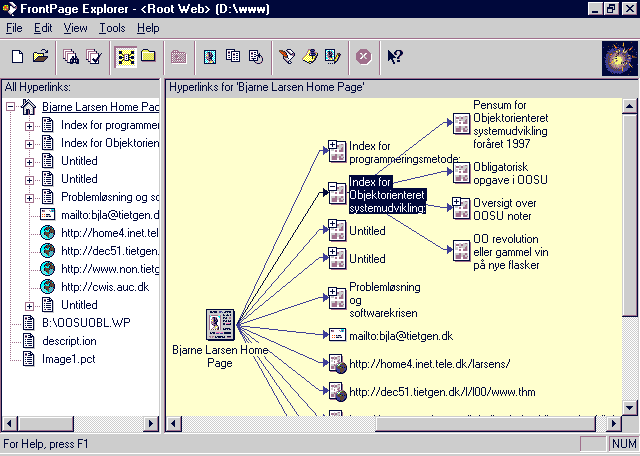
Figur 2-5.
Et øjebliksbillede fra Frontpage.En syntaks-dirigeret editor er en struktur-orienteret editor, hvor den struktur, der arbejdes på, er defineret og afgrænset af en grammatik for et konkret programmeringssprog.
Ideen bag den syntaks-dirigerede editor er, at man editerer dokumenterne ved hjælp af syntaktiske templates i stedet for simpel lineær tekst. De syntaktiske templates vil som regel være hierarkiske. Billedet i figur 2-5 kan i denne forbindelse tjene som eksempel på, hvordan en hierarkisk opbygget template kan se ud.
Forskellen i forhold til den tekst-orienterede editor med indbygget strukturel hjælp ligger i, at man i den syntaks-dirigerede editor er tvunget til at bruge de indbyggede templates, hvor man i den tekst-orienterede editor kunne kalde den strukturelle hjælp frem, når man ønskede det.
2.2.2 Oversættere, fortolkere og linkere
Man skelner mellem oversættere (compilere) og fortolkere.
En compiler oversætter et program skrevet i kildetekst (sourcecode) til et program i maskinkode (objectcode). Denne metode giver nogle fordele, hvoraf de vigtigste er en effektiv udførelse på maskinen og muligheden for at udføre type check under oversættelsen.
En fortolker er kendetegnet ved, at programmet oversættes og udføres i samme arbejdsgang. Den vigtigste fordel ved denne metode er, at programmet er let at afprøve, fordi det ikke skal oversættes først.
Formålet med disse værktøjer er at opnå, at det programmøren skriver, bliver transformeret til noget, som computeren kan forstå. Undervejs foretager værktøjet de nødvendige checks og udskriver fejlmeddelelser, hvis det viser sig nødvendigt.
I dette afsnit vil vi give en kort, generel beskrivelse af disse værktøjer, og vi vil give vores bud på, hvilke komponenter, de skal indeholde, og hvorledes de hensigtsmæssigt skal skrues sammen og fungere for at kunne være til optimal støtte for programmøren.
Der er reelt set tale om en række værktøjer, hvis indbyrdes afhængighed og rækkefølge er systemspecifik. En generel sammenhæng er vist i figur 1-2. Fortolkeren er et værktøj, som er i stand til at compile, linke og eksekvere i en arbejdsgang, og vil derfor ikke blive beskrevet særskilt med hensyn til indhold.
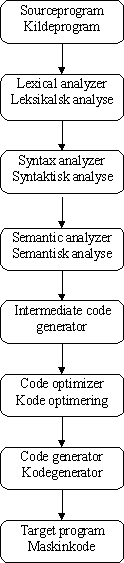
Figur 2-6.
Delaktiviteter i compiler processenI figur 2-6 er vist en mere detaljeret aktivitetsopdeling af processen "Compiler" fra figur 1-2:
Leksikalsk analyse går ud på at få delt kildeteksten op i hensigtsmæssige objekter - de såkaldte tokens. Eksempler på tokens er variabler, keywords. Disse tokens får tildelt en intern repræsentation og de bliver lagt ind i, hvad man kunne kalde programmets indholdsfortegnelse (symbol table).
Moderne programmeringssprog er opbygget på baggrund af en kontekstfri grammatik - et begreb, som første gang blev defineret af Bachus og Naur i [Bachus63]. At man bygger på en kontekstfri grammatik betyder, at programmøren må underlægge sig et forholdsvis stramt regelsæt med hensyn til formulering af programmets sætninger.
Dette viste sig at være den mest fordelagtige vej, fordi programmer skrevet i programmeringssprog med en friere syntaks (f.eks. PL/1) ofte viste sig omkostningstunge at vedligeholde. En anden, ikke uvæsentlig, årsag var at compilerne konstrueret på baggrund af en kontekstfri grammatik er nemmere at skrive og dermed også mindre fejlbehæftede.
Den kontekstfrie grammatik er implementeret i syntax analyzeren, og resultatet af denne delproces er en hierarkisk repræsentation af programmet.
I semantic analyzer samles diverse information op omkring programmets bestanddele - populært sagt kan man sig, at de træer, som konstrueredes i syntax analyser, "dekoreres" med yderligere information. Endelig foregår her en meget vigtig aktivitet: type checking, som går ud på at tilsikre, at de forskellige variabler og datafelter anvendes korrekt. En ulovlig handling her kunne for eksempel være at prøve at få programmet til at uddrage kvadratroden af et tekstfelt.
De dekorerede træer er input til intermediate code generator, som producerer en ny kode, som kaldes "three address code". Fordelen ved dette ekstra trin er, at man kan indlægge et ekstra trin, som optimerer koden (code optimizer), inden den endelige kode genereres af code generator.
Optimeringen er fordelagtig, fordi den kan fjerne (nogle af) uhensigtsmæssighederne i det oprindelige program og dermed producere et mere effektivt program.
Output fra code generator kaldes target assembly program, og Aho, Sethi og Ullman [Aho86] afviger fra figur 1-2 ved at have et ekstra trin inde, før linkage-editor tager over, nemlig den såkaldte assembler. Man kan imidlertid også vælge at opfatte den som en del af compileren.
Fejlmeddelelser er efter vores mening et helt centralt fænomen for så vidt angår compilerens kvalitet. Problemstillingen omkring fejlmeddelelser er et stort og ganske vanskeligt område, som ethvert softwareprodukt må forholde sig til, og alle edb-brugere har formentlig oplevet at få, hvad de selv kun kunne betegne som en ubrugelig og dermed tåbelig fejlmeddelelse. [For en elementær og også en anelse populistisk fremstilling af problemerne omkring gode og dårlige fejlmeddelelser se [Molich95] ]
Compilere er også et softwareprodukt, og gode og sigende fejlmeddelelser på rette tidspunkt og i det rette omfang forbedrer brugerens - i dette tilfælde programmørens - effektivitet. Af betydning for, hvorledes brugeren oplever compilerens faktiske håndtering af fejl. Den mest anvendte strategi ved leksikalske eller syntaktiske fejl er nok ‘panic mode’, hvor compileren læser videre, indtil den finder noget, den kan genkende. En anden strategi går ud på at forsøge at rette fejlen. Se for uddybning [Aho86].
En anden vigtig pointe omkring compilerens kvalitet er, at den ikke producerer flere repræsentationer af programmet, som skal administreres, end højest nødvendigt. Den optimale løsning er et såkaldt "uni-representational environment" [Nørmark89], hvor programmet kun eksisterer i én repræsentation.
At holde sig nede på kun én repræsentation, kan dog afstedkomme en hel del praktiske problemer, og beslutningen vedrørende antal repræsentationer må naturligvis bero på en afvejning af fordele og ulemper; men det er klart, at jo flere forskellige repræsentationer, der skal administreres, jo større er sandsynligheden for fejl og inkonsistens. Dette aspekt uddybes i afsnittet om integration.
Compilere kan designes til at finde flere eller færre fejl i programmerne (men aldrig dem alle - se næste afsnit). Igen må der være tale om en afvejning af fordele og ulemper. Fordelen ved at fange mange fejl er, at det letter programmørens arbejde - ulempen er, at det tager længere tid at afvikle sin compilering på computeren.
I en tid hvor CPU-tid stadig bliver eksplosivt billigere og computerne eksplosivt hurtigere, kan man let argumentere for, at compileren skal finde så mange fejl som muligt; men det kunne godt se ud som om compilerkonstruktører enten er et konservativt folkefærd eller er bundet af fortidens synder.
Ethvert større program er kun fejlfrit, indtil man finder den næste fejl. Dette selvopfundne tankesprog gælder naturligvis også for compilere, og antallet af fejl kan som nævnt reduceres ved at basere sin syntaks på en kontekstfri grammatik. Desuden kan man sige at en gammel, velafprøvet compiler, alt andet lige, vil indeholde færre fejl end en ny og uafprøvet, hvilket taler for at bruge en ældre model.
Som regel er fejl i velafprøvede compilere ikke noget større problem for programmøren; men de kan selvfølgelig blive det, hvis fejlene er forholdsvis uigennemskuelige, for eksempel hvis compileren genererer fejlbehæftet kode.
Sammenfattende kan vi opstille følgende kriterier til vurdering af en compiler:
Vi startede med at skelne mellem compilere og fortolkere og vil nu kort opridse de vigtigste fordele ved hver af disse. Ulemperne findes ved at vende fortegn hos den anden. Compilerens vigtigste fordel er en effektiv udførelse på maskinen og muligheden for at udføre type check under oversættelsen.
Den vigtigste fordel ved fortolkeren er, at programmet er let at afprøve, fordi det ikke skal oversættes først. I øvrigt henvises til kapitel 1, hvor emnet er uddybet, idet vi fandt det mere relevant at gøre dette i den historiske sammenhæng.
Lænkerens (linkerens) opgave er at samle en række forskellige programmoduler til en eksekverbar helhed. Kernen i denne helhed er det modul, som programmøren har udpeget som hovedmodulet. Heromkring samles de programmørdefinerede undermoduler og de systemmoduler, som følger med operativsystemet eller med oversætteren.
Der er egentlig ikke så forfærdelig meget at sig om lænkeren med hensyn til, hvad den skal kunne , bortset fra det helt trivielle, at den skal virke og være nem at bruge. Vi vender tilbage til lænkeren i afsnittet om integration.
I dette afsnit vil vi kort defineres værktøjets baggrund og formål. Herefter vil vi diskutere typiske karakteristika ved debuggere og til sidst give et bud på, hvad en god debugger, efter vores mening, bør indeholde.
Der er i tidens løb foretaget mange undersøgelser for at få godtgjort, hvor lang tid de enkelte aktiviteter belaster et edb-systems udviklingstid med. Her har det vist sig at test-aktiviteten er en af de længstvarende [Brooks95] og mest kritiske for systemets succes.
Test er således et meget stort emne i systemudviklingsprocessen, dels findes der mange forskellige typer af tests i stort set hele processen, og selv en aktivitet som fremskaffelse af brugbare og repræsentative testdata bør give anledning til mange, herunder også teoretiske, overvejelser. I det efterfølgende har vi valgt at begrænse os til det generelle plan, og dermed vil vi ikke gå ind og vurdere debuggers i forbindelse med hver enkelt testtype.
[En sådan yderligere detaljering af emnet debuggers er yderst relevant, især for større programkomplekser; men vi vurderer, at det falder uden for dette speciales rammer.]Eftersom debuggeren kan defineres som det værktøj, der skal hjælpe programmøren med at finde fejl i programmet, er dette værktøj naturligvis af stor betydning. Hos Nørmark [Nørmark89] er debuggeren beskrevet under en kategori kaldet "programming examination", hvorunder også andre værktøjer beskrives.
Vi har valgt at beskrive debuggeren, idet det er vores erfaring, at fornuftigt debugging værktøj er af uvurderlig betydning for programmøren i udviklingsarbejdet og kan forbedre produktiviteten betragteligt. Afsnittets overskrift skal ses som et udtryk for at den aktivitet, der består i at finde fejl i et program ikke nødvendigvis kun finder sted under anvendelse af debuggeren.
Den "ultimative" debugger ville være et program, som kunne tage et hvilket som helst program og dets specifikation som input og alene på baggrund heraf afgøre, om programmet var i orden eller ej. Desværre lader dette sig imidlertid ikke gøre, idet den slags problemer henregnes til de såkaldte uafgørbare problemer [Sipser96], hvorom man matematisk har bevist, at de ikke lader sig løse på computer.
Endvidere kan specifikationers entydighed i høj grad diskuteres, og det er muligvis slet ikke noget at stræbe efter, idet de så skal skrives i deres eget programmeringssprog [Naur82 og Polak 80], og man herved blot tilføjer et ekstra lag i processen.
Programmøren er altså henvist til at finde fejlene selv, og et af de helt afgørende forhold omkring hans muligheder herfor er i hvor høj grad, det lader sig gøre at genskabe situationen (systemets nøjagtige tilstand), hvorunder fejlen opstod. Dette problem er især kritisk i store multi-user applikationer og applikationer med parallel processing; men selv i mindre, single-user miljøer kan det vise sig vanskeligt at genskabe en fejl.
Vi har stadig til gode at møde konkrete, brugbare anvisninger på løsning af dette problem; men det hænger sandsynligvis sammen med problemets natur. Ofte er man som programmør henvist til at opfordre brugere til straks, når fejl opstår, at dokumentere systemets tilstand så præcist som muligt, dvs. blot skrive ned hvilke kommandoer de netop har udført og hvilke data de har arbejdet på.
Den mest simple form for debugging står programmøren selv for. Den går ud på at indsætte statements i sourcekoden på steder hvor programmets tilstand er kritisk, f.eks. lige før det går ned, hvor værdien af centrale variable eller datafelter udskrives. På trods af metodens enkelhed viser den sig ofte særdeles effektiv, især for folk med en del erfaring.
I alle de programudviklingsmiljøer, vi er bekendt med, er ovennævnte form for debugging mulig.
Hvis man arbejder med et egentligt værktøj vedrører de mest anvendte simple teknikker tracepoints og breakpoints [Nørmark89].
Et breakpoint, angiver en position i programmet hvor man ønsker at stoppe udførelsen og inspicere indholdet af variabler og datastrukturer, for derefter at kunne fortsætte programafviklingen.
Et tracepoint er ligeledes en bestemt position i programmet, som kan markeres, og hver gang bemeldte position passeres, sender debuggeren en informativ meddelelse.
De fleste debuggers muliggør også at "trace" (spore) enkelte variabler eller datafelter. Det betyder at debuggeren holder styr på hvilke værdier, de udpegede felter har haft under programafviklingen, og hvor og hvornår de er blevet modificeret [Kamkar86].
En anden nyttig debugger facilitet er markering af udførte statements. Dette kan især være fordelagtigt, hvis man ønsker at få identificeret "død kode", altså kode som aldrig eksekveres. Denne problemstilling opstår hyppigst i forbindelse med vedligeholdelse af større, ældre mainframe-applikationer.
Endelig vil vi kort omtale, hvad man kunne kalde avancerede debuggers. Her er der tale om, at man har defineret et (kommando)sprog, hvormed programmøren kan kommunikere med debuggeren, dvs. stille relevante spørgsmål og så forhåbentlig få brugbare svar.
For at få udbytte af at arbejde med egentlige debugger sprog, kræves det, at man bruger værktøjet ofte, da man ellers hurtigt glemmer det igen. Til løsning af dette problem foreslår [Nørmark89], at man bruger selve programmeringssproget som debuggersprog. Det lyder besnærende; men langt fra alle programmeringssprog egner sig til denne opgave. I det lange løb vil det nok være mere effektivt at anvende et særskilt kommandosprog.
Den vigtigste karakteristik for en debugger er efter vores mening, at den er et "ægte" værktøj [Sørgaard88], dvs. at man ikke tænker over, hvordan man skal bruge det, men retter sin koncentration mod den opgave, der skal udføres. Debuggeren bør indeholde muligheder for trace- og breakpoints og endelig skal den være trimbar med hensyn til de informationer, den afleverer. Effektiviteten ved at arbejde med debuggers falder ofte mærkbart, hvis programmøren druknes i information, som han ikke har mulighed for at begrænse.
I 1982 slog Ehud Y. Shapiro fast, at "debugging is a messy problem", hvilket vel bedst oversættes ved: "debugging er et bøvlet problem" [Shapiro82]. De mange teoretiske tiltag på området og fremkomsten af en lang række nye debuggers i de seneste 15 år, har ikke ændret det mindste ved sandhedsværdien af dette udsagn.
I dette afsnit vil vi give nogle kortfattede bemærkninger omkring job kontrol sproget og dermed operativsystemets indflydelse på programudviklingsmiljøet. Selve job kontrol sproget adskiller sig ikke væsentligt fra andre programmeringssprog.
Der er normalt mulighed for at variere de enkelte kommandoer med parametre og options, ligesom mange job kontrol sprog indeholder kontrolstrukturer, som man kander det fra de egentlige programmeringssprog. Det kan f.eks. dreje sig om betinget udførelse af en kommando eller gentagelse af en kommando.
Et andet typisk aspekt ved job kontrol sprog, som også kendes fra de egentlige programmeringssprog, er muligheden for at udføre en procedure.
Vores synspunkt er, at operativsystemets fleksibilitet og med et fortærsket udtryk brugervenlighed kan have stor indflydelse på programmørens effektivitet især i testfasen. Dette kan bedst illustreres med et eksempel. I DOS og Unix kan man opdatere en fil med en tekststreng ved hjælp af en enkelt kommando. I IBM’s mainframe operativ system skal man minimum kalde en utility ved hjælp af en jobstrøm, som skal indtastes i en editor, og resultatet af jobbet skal checkes seperat. Unægtelig en besværlig måde at løse en simpel operation på. Under sådanne omstændigheder kan det blive endog meget tidskrævende at etablere et fornuftigt testmiljø samt at retablere samme. Aktiviteter som set ud fra programmørens synspunkt bør være ren rutine og kunne foregå meget hurtigt.
I dette afsnit vil vi se på CASE-værktøjers
[CASE ~ computer aided software engineering]anvendelighed i programudviklingsprocessen.
De fleste CASE-værktøjer kan opfattes som totale systemudviklingsmiljøer, idet de også forsøger at tage hånd om aktiviteter, der i den traditionelle vandfaldsmodel typisk går forud for programmeringsaktiviteterne: analyse og design. Intentionen med en række CASE-værktøjer har således været, at få hele processen fra analyse til implementering til at hænge bedre sammen, idet et stort problem i systemudviklingsprocessen har været manglende konsistens mellem systemets forskellige versioner, dvs. der ender med at være uoverensstemmelse mellem analysedokumentet, designdokumentet og det realiserede system. Integration i programudviklingsmiljøøet og CASE-værktøjer hænger således konceptuelt en hel del sammen, men dog ikke mere, end at vi anser det for forsvarligt at behandle emnerne hver for sig.
Man kan dog også skelne mellem såkaldte upper-case og lower-case værktøjer. Upper-case dækker over værktøjer til brug i forbindelse med de mere reflekterende faser af systemudviklingsarbejdet, foranalyse, analyse og design. Lower-case dækker tilsvarende de realiserende faser programmering og test.
En af ideerne med CASE-værktøjer for så vidt angår programudviklingsprocessen var at mindske antallet af fejl og dermed forbedre produktiviteten. Ideen var at foretage en del af compileringen dynamisk, dvs. mens programmet blev tastet ind, eller at tvinge brugeren til kun at anvende syntaktisk korrekte tokens.
[Et token er populært sagt en tekststreng, som en compiler kan gen- og godkende, [Aho86] ] På den måde bliver værktøjet i stand til umiddelbart at foretage alle syntakscheck og en række typecheck, og det kan umiddelbart virke som en stor fordel. I praksis viser erfaringer med anvendelsen af konkrete værktøjer som f.eks. IEF, [IEF ~ Information Engineering Facility - et Texas Instruments CASE-værktøj, baseret på James Martin’s systemudviklingsmetode] at fordelen er til at overse. I praksis får man blot et ekstra lag af kode, som også skal administreres, og det forhold at alting skal hænge sammen, medfører at selv små ændringer i datamodellen, bliver meget tidskrævende. [En større dansk edb-virksomhed, som bruger IEF, har set sig nødsaget til at indføre den praksis at hvis man ønsker at rette i et kørende program, skal programmet bestilles dagen i forvejen, hvorefter det downloades om natten og hvis korrektionen tager under en dag kan der således promotes den følgende dag, dvs. at turn-around tiden for en ændring altid er mindst 24 timer. Det virker unægtelig som en høj pris at betale for en konsistent model.]At CASE-værktøjerne ikke har fået den udbredelse, som de blev spået for en lille halv snes år siden, beror især på det forhold, at de ikke tilnærmelsesvis var i stand til at indfri de forventninger, som sælgerne af produktet lovede. Nogle værktøjer lovede produktivitetsforbedringer på op mod 100% i løbet af bare tre år i forhold til traditionelle metoder og udviklingsværktøjer. Realiteterne viste, at efter fem års brug slås mange købere stadig med at påvise forbedringer i det hele taget. Desuden hvilede visse af produkterne på den, efter vores mening, fejlagtige antagelse, at en virksomheds grundlæggende data- og processtruktur er statisk, og at man kan derfor sænke systemers vedligeholdelsesomkostninger dramatisk, hvis disse strukturer bringes på plads en gang for alle.
Vi kan ikke umiddelbart anbefale anvendelse af CASE-værktøjer til udvikling af administrative edb-systemer. Prisen er for høj. Ikke blot påfører man programmørerne administrativt tunge procedurer, man risikerer også at dræbe deres kreativitet og motivation. Nogle af ideerne er imidlertid gode nok, hvis de anvendes med omtanke. Grafisk repræsentation af datastrukturer er en udmærket ide, især hvis de er nemme at udskrive på papir.
[Bemærkningen er ikke helt så banal, som den umiddelbart kan virke. Mange programudviklingsmiljøer udviser en forbløffende dårlig evne til udskrift af programobjekter. Det kan skyldes, at udviklerne af disse mener, at papir hører fortiden til - et synspunkt, vi er helt uenige i. Det bedste overblik over et større program fås uden tvivl ved en ‘pretty-printer’ udskrift på papir i endeløs bane.] At få fat i alle syntaksfejlene og den del af de semantiske fejl, det nu lader sig gøre at fange på indtastningstidspunktet, er utvivlsomt også en fordel.
2.3 Integration, inkrementalitet og interaktivitet
Nørmarks definition af programmeringsomgivelsen begrænser sig alene til den proces hvorunder programmets livscyklus befinder sig, og lægger sig dermed forholdsvis tæt op ad den traditionelle faseopdelte systemudviklingsmodel. Eller man kan måske, med risiko for overfortolkning, sige, at han mener, at programmering med fordel kan udskilles fra systemudviklingsprocessen.
Det er vores antagelse, at begrundelsen herfor primært skal ses i lyset af tre forhold:
Med de nyere udviklingsmetoder og udviklingsværktøjer tror vi ikke på, at denne udskilning længere er hensigtsmæssig. Programmering kan forekomme stort set hvor som helst i systemudviklingsprocessen
I dette afsnit vil vi derfor tage udganspunkt i Nørmarks definitioner og afgrænsninger hvad angår begrebet integration, og i det omfang, vi finder det nødvendigt, vil vi udvide rammerne for disse, så de er i stand til at beskrive relevante kriterier for et visuelt programudviklingsmiljø.
Vi vil derudover se på to andre vigtige forhold omkring programudviklingsprocessen, som vi vil sideordne med integration, nemlig inkrementalitet og interaktivitet.
[På trods af, at begreberne inkrementalitet og interaktivitet ikke er helt mundrette, har vi valgt at bruge disse fordanskede begreber i stedet for de tilsvarende engelske begreber, incrementality og interactiveness.] Nedenstående definitioner er inspireret af Nørmark [Nørmark88] og Hedin og Magnusson [Hedin86].Vi har allerede været en hel del inde på forskellige forhold om alle tre bereber i den historiske gennemgang i kapitel 1, og de vil kun, hvor vi forståelsesmæssigt har fundet det påkrævet, blive gentaget her.
Integration definerer vi på følgende måde:
integration er et mål for i hvilken udstrækning tingene hænger sammen - i denne forbindelse primært de forskellige repræsentationer af programmet
Inkrementalitet definerer vi på følgende måde:
inkrementalitet er et mål for i hvilken udstrækning tingene kan bygges op af mindre enheder for til sidst at udgøre et sammenhængende hele, dog således, at de indgående enheder fortsat kan isoleres
Interaktivitet definerer vi på følgende måde:
interaktivitet er et mål for i hvilken udstrækning tingene kan udføres i dialogform - primært mellem program og programmør
I forbindelse med integration kan man diskutere de forskellige repræsentationer et program kan have på forskellige tidspunkter i udviklingsprocessen. Et program kan f.eks. eksistere i en af følgende tilstande:
Umiddelbart lyder det som et mål i sig selv at begrænse antallet af repræsentationer, fordi administartionen og mulighederne for fejl og inkonsistens dermed mindskes. Der er dog også grænser for, hvor få repræsentationer man kan nøjes med, hvis man skal kunne fastholde en fornuftig eksekveringshastighed.
Integrationen af værktøjerne kan omfatte:
Nørmark [Nørmark89] bruger mange kræfter på at etablere et begrebsapparat omkring integration og opstiller forskellige teser herom. Frem for at referere mere eller mindre direkte, vil vi indskrænke os til at vælge den model for integration, vi synes bedst om, og give vores berundelser herfor.
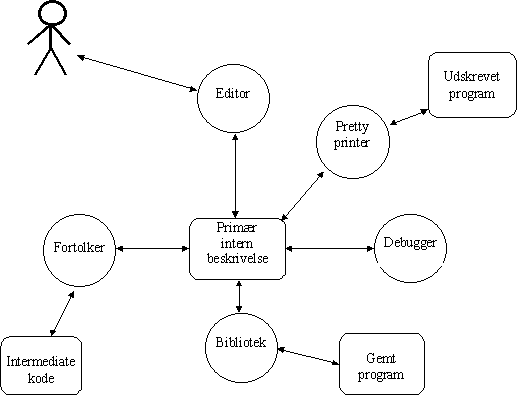
Figur 2-7.
Forholdet mellem værktøj og repræsentation i et integreret programudviklingsmiljø. [Inspireret af figur 4.9 side 41 i [Nørmark89] ]Det overordnede hensyn ved vores valg af model vedrører balance. Fordele og ulemper ved få, henholdsvis mange repræsentationer skal ikke gentages. Vi finder ovenstående model passende, fordi den tilgodeser vigtige aspekter i programudviklingsmiljøet som administration (gemt program) og sammenhængende udskrift (udskrevet program), og endelig tilgodeser den behovet for effektiv afvikling (intermediate kode), uden at ideen om en central version går tabt.
Inkrementalitet kan bedst beskrives ved hjælp af et eksempel fra det traditionelle programudviklingsmiljø, nemlig ved at betragte lænkerens rolle. Den tager sig af at hæfte compilerede moduler sammen til noget eksekverbart, og tingene fungerer, således at kun de ændrede moduler, skal omcompileres.
Samme princip kendes fra makroer og præ-processorer til compilere, som bl.a. bruges til at inkludere definitioner af datastrukturer i programmet fra et bibliotek for at tilsikre, at alle anvender det samme sæt definitioner.
Hedin og Magnusson [Hedin86] koncentrerer sig om inkrementalitet i forbindelse med eksekvering af programmer, og prøver at udbygge ovenstående koncept, således at inkrementalitet kan opnås helt ned på blokniveau i det enkelte programmodul. Ideen er - kort fortalt - at det skal være muligt, at foretage rettelser flyvende, uden hver gang at skulle starte helt forfra.
Hvis man forestiller sig programmet hierarkisk repræsenteret i form af et træ, skal det være muligt at rette i en intern node og fortsætte eksekvering herfra, således at foregående og efterfølgende noder med børn forbliver uændrede, og ændringen kun kommer til at påvirke den ændrede node med børn.
Problemstillingen er, hvor banal den end kan lyde, yderst kompleks, og for flere moderne CASE-værktøjer er den på ingen måde løst tilfredsstillende. Selv yderst simple ændringer i kørende programmer kan få den dominoeffekt, at et (uforståeligt) stort antal programmer og modeller skal genoversættes, for at ændringen kan blive effektiv. Dette kræver selvsagt større ressurceallokering til administrative aktiviteter.
Vores synspunkt omkring inkrementalitet er, at programudviklingsmiljøet bør støtte dette i udstrakt grad, idet der dermed kan opnås ganske betydelige tidsbesparelser for den erfarne programmør. Prisen herfor kan på den anden side være, at man mister overblikket over systemet, hvis det bliver delt op i for mange stumper og/eller snarere fragmenteret end segmenteret. Her gælder det om, at finde en fornuftig balance.
En "tilstødende" problemstilling til inkrementalitet vedrører udviklingsmiljøets evne til at håndtere mange, store eller små programmer.
[Programming-in-the-many, programming-in-the-large, programming-in-the-small] Vi anser dette for et yderst vigtigt kriterium i en Verden, hvor man oplever en stigende specialisering på bekostning af ‘all-purpose’ værktøjer, og det derfor er endnu vigtigere end tidligere at vælge det rigtige værktøj/miljø i den rigtige situation. [Virkeligheden for mange systemudviklere er, at man reelt ikke har noget valg med hensyn til værktøjer, når en ny applikation skal udvikles. Man oplever også forbavsende ofte, at folk, hvis de har et valg, vælger at bruger værktøjer, som de kender i forvejen, også selv om værktøjerne slet ikke egner sig til opgaven] Problemstillingen blev beskrevet af Demer & Kron i 1976 [Demer76], og siden har bl.a. Lars Bendix [Bendix93] videreudbygget modellen.Udover at beskrive interaktive programudviklingsmiljøer
[Se for eksempel Agentsheets [Repenning95] ] er kilderne ret sparsomme på dette område, så vi vil fortrinsvis øse af egne erfaringer og synspunkter i dette afsnit.For godt 20 år siden, da stort set al kommericiel databehandling foregik på mainframes var det interaktive element i programudviklingsmiljøet noget nær nul. Typisk afleverede programmøren sit kortdeck eller hulstrimmel i driftsafdelingen, og fik resultatet tilbage et par timer senere i form af en papirudskrift. Hvis der for eksempel havde været fejl i job kontrol kommandoerne, kunne han så rette denne fejl og vente to timer yderligere.
Det siger sig selv, at med denne noget tunge arbejdsform kunne man se frem til ganske betydelige produktivitetsforbedringer, hvis det interaktive element i programudviklingsmiljøet blev forbedret. Der blev derfor brugt mange kræfter på dette område, og resultaterne udeblev ikke, selvom de nok ikke blev helt så gode som forventet.
Årsagen skal findes i det forhold, at mange programmører skiftede arbejdform, da de mange interaktive faciliteter blev tilgængelige. Hvor man før havde begravet sig i timevis i sin programudskrift og udført den ene skrivebordstest efter den anden og rettet adskillige fejl, før man fyrede det næste testskud af, blev det nu en nærliggende mulighed at lade computeren finde fejlene, dvs. at man rettede en fejl pr. testskud.
Konsekvensen af denne arbejdsform er imidlertid, at man qua den manglende fordybelse mister overblik over sit program. Da hver mand fik sin skærm i starten af firserne gik det også af mode, at skrive sine programmer ud på papir, hvilket blot forstærkede før omtalte udvikling. Resultatet af disse ændrede arbejdsformer betød, at for mere komplicerede programmers vedkommende kom testen til at udgøre en forholdsmæssig større andel af programudviklingsforløbet end tidligere, og vedligeholdelsesomkostningerne snarere voksede end faldt, fordi programmørerne ikke havde det samme overblik over programmerne som før.
[Denne påstand bygger på en stærk fornemmelse, som vi dog ikke kan dokumentere.]En høj grad af interaktivitet i programudviklingsmiljøet er altså et tveægget sværd. På den ene side kan det give produktivitetsforbedringer; men det kan blive på bekostning af overblikket. Vi tror, at den programmør, som virkelig kan udnytte fordelene ved det interaktive miljø, skal have lyst og vilje til forbdybelse og skabelse af overblik, når det er nødvendigt. I gamle dage var det en livsnødvendighed, hvis man overhovedet ville have sine programmer til at virke - i dag kan man slippe afsted med en langt mere sjusket arbejdsform.
Ovenstående udredning er et meget godt eksempel på et synspunkt, som vi anser for helt grundlæggende i al systemudvikling og dermed også programmering. Værktøjerne betyder højest 20% - resten, dvs hele 80%, har med personens kvalifikationer at gøre, og her spiller de bløde kvalifikationer en ikke ubetydelig rolle.
Vores konklusion på interaktivitet er, at det selvfølgelig er vigtigt, at den er til stede i et rimeligt omfang, således at man ikke spilder en masse tid med trivielt arbejde.
[Se afsnit 2.2.4 om job kontrol sprog] Omvendt skal den heller ikke tildeles for høj prioritet på bekostning af andre vigtige egenskaber ved et programudviklingsmiljø, og man bør være meget opmærksom på at tilstræbe hensigtsmæssige arbejdsmetoder i et stærkt interaktivt miljø.
Vi indleder dette afsnit med at se på de forskellige aktiviteter i systemudviklingsprocessen. Vi er især interesseret i forholdet mellem selve realiseringen (programmeringen) og de reflekterende aktiviteter, som er den anden del af systemudviklingen.
Det er vigtigt at fremhæve, at den ene aktivitet ikke er en forudsætning for den anden; men at de to aktiviteter gensidigt påvirker hinanden. En passende vekslen mellem de to forskellige aktiviteter er til lige stor gavn og en inspirationskilde for arbejdet i begge aktiviteter. De to aktiviteter er altså nærmest hinandens forudsætninger.
2.4.1 Programudvikling som led i systemudvikling
Formålet med aktiviteten programudvikling er realiseringen af en løsning på et problem ved hjælp af den computerhardware, brugeren har til rådighed; men som vi nævnte allerede i det første kapitel indgår aktiviteten i en større og mere omfattende aktivitet, som vi kalder systemudvikling.
Nørmarks opfattelse af formålet med den omsluttende systemudviklingsaktivitet er, at systemudvikling primært beskæftiger sig med processen at fremstille den specifikation, der kan danne grundlag for fremstillingen af programmet. [Nørmark89]
Baggrunden for denne opfattelse er en idé om, at den ene aktivitet (systemudvikling) er en forudsætning for den anden (programmering), og at de to aktiviteter derfor kan forstås og beskrives uafhængigt af hinanden.
Heroverfor står den opfattelse, som bl.a. kommer til udtryk hos Pål Sørgaard [Sørgaard88], at det i praksis er umuligt at holde de enkelte aktiviteter adskilt fra hinanden. Pål Sørgaard var medforfatter til bogen "Professionel systemudvikling" [Andersen86], som efter vor mening er et meget tungtvejende bidrag til forståelse af, hvad systemudvikling dybest set går ud på.
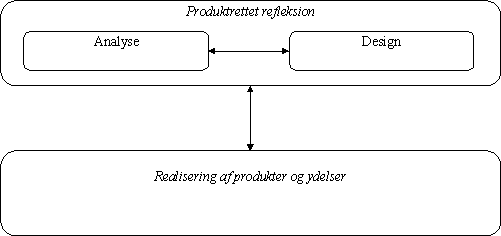
Figur 2-8.
Samspillet mellem de forskellige aktiviteter i systemudvikling.I bogen "Professionel systemudvikling" når man bl.a. frem til to teser om forholdet mellem de enkelte aktiviteter i systemudviklingen. Den første lyder:
Analyse og design forudsætter hinanden, og de bør derfor udføres i gensidigt samspil.
De to aktiviteter, analyse og design, kaldes under ét for produktrettet refleksion, og når man ser dette i sammenhæng med realiseringen, kommer man frem til den anden tese:
Produktrettet refleksion (analyse og design) og realisering påvirker hinanden, og de bør derfor udføres i gensidigt samspil.
Samspillet mellem de forskellige aktiviteter kan illustreres med en tegning, som vist i figur 2-6. [Inspireret af figur 3.3 side 46 i Professionel systemudvikling.]
Grundfilosofi
Systemmudviklingsprocessen kan karakteriseres ved den grundfilosofi, som forståelsen af opgaven i udviklingsprocessen bygger på. Man kan også kalde disse grundfilosofier for grundlæggende abstraktionsteknikker:
Meget ofte anvendes betegnelsen paradigme om det, som vi her har kaldt grundfilosofier; men efter vor mening er paradigme ikke det rigtige ord. Begrebet paradigme kendes bl.a. fra videnskabsteorien, hvor det dækker over det fænomen, at en man indenfor en bestemt videnskab kan have en samling af sammenhørende teorier, som på tilfredsstillende måde forklarer de observationer, man kan gøre i den pågældende videnskabs problemområde.
Paradigmerne bliver faktisk først rigtig synlige, når man indenfor en videnskab begynder at foretage observationer, der ikke kan forklares ud fra de kendte teorier. I begyndelsen prøver man at justere teorierne, så de også kan forklare de nye observationer; men efterhånden bliver teorierne så indviklede, at de bliver umulige at håndtere.
I en sådan situation kan det ske, at der er nogle, der begynder at lede efter en ny og enkel teori, der både kan forklare de gamle og de nye observationer. Det svære ved at finde frem til de nye teorier er, at det ofte forudsætter, at man er i stand til at se bort fra eller arbejde som om den gamle teori ikke eksisterede.
Med til historien hører også, at man må forvente sønderlemmende kritik fra det etablerede videnskabelige samfund. Det kan derfor være svært at skaffe midler til at drive den grundforskning, der kan bane vejen for den nye teori. Hvis man på trods af alle de hindringer, der bliver lagt i vejen for én, alligevel når frem til en ny teori, vil man ofte kalde den opståede situation for et paradigmeskift.
Vi synes, at dette begreb skal være forbeholdt de store og ofte dramatiske ændringer, der undertiden sker i det videnskabelige verdensbillede. Vi er bange for, at begrebet bliver udvandet og mister sin kraft, hvis det skal anvendes om alle de større eller mindre påståede teknologiske gennembrud, der forekommer indenfor systemudviklingen. Derfor foretrækker vi betegnelsen grundfilosofi eller grundlæggende abstraktionsteknik.
Med hensyn til de nævnte abstraktionsteknikker er det vanskeligt at sige, hvilken der er den bedste - det vil i alle tilfælde afhænge meget af situationen og ikke mindst opgavens art. Der er til gengæld ingen tvivl om, at objektorientering er den abstraktionsteknik, der tiltrækker sig den største opmærksomhed for øjeblikket; men at objektorienteret abstraktion skulle være en mere naturlig måde at abstrahere på end f.eks. top-down, har vi i hvert fald ikke set beviser på. Vi vil derfor heller ikke opstille krav om, at programudviklingsmiljøet skal understøtte en bestemt grundfilosofi.
Arbejdsform
Systemudviklingsmiljøet er på den anden side også være karakteriseret ved den arbejdsform, man foretrækker at bruge i processen:
Det er med henvisning til Pål Sørgaard [Sørgaard88] og ikke mindst "Professionel systemudvikling" [Andersen86] nødvendigt at stille krav til programudviklingsmiljøet om, at det understøtter en eksperimenterende arbejdsform, idet denne arbejdsform er en forudsætning for at der kan opstå den beskrevne vekselvirkning mellem de reflekterende aktiviteter på den ene side og den realiserende aktivitet på den anden side.
Forskellige indfaldsvinkler til systemudviklingsprocessen
Et interessant spørgsmål i forbindelse med udviklingen indenfor systemudviklingsmiljøet er, hvordan den stadige udvikling af nye og bedre værktøjer til realisering påvirker hele systemudviklingsprocessen. Til illustration af fænomenet vil vi i de følgende tre afsnit forsøge at vise, hvordan systemudviklingsprocessen kan opfattes i traditionel (vandfaldsmodel), objektorienteret og visuel systemudvikling. Som sagt vil vi primært koncentrere os om den rolle, realiseringen spiller i forhold til systemudviklingsprocessen som helhed.
I hvert enkelt tilfælde vil vi prøve at beskrive vores opfattelse af systemudviklingen ved hjælp af et diagram, der indeholder en opdeling af rummet som vist i den følgende figur 2-9.
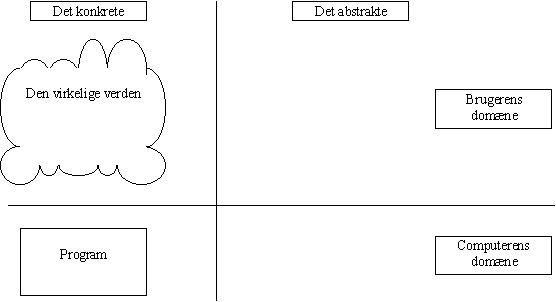
Figur 2-9.
Principskitse til beskrivelse af systemudviklingsprocessenIdeen med diagrammet er at vise, hvordan systemudvikling udfolder sig i to forskellige dimensioner. [Inspirationskilden til dette diagram er usikker. En af os kan huske det fra noget ikke publiceret kursusmateriale. Blandt ophavsmændene til det pågældende kursusmateriale hører i hvert fald Lars Mathiassen; men vi er ikke sikre på, om han er den egentlige ophavsmand.] Målet med systemudvikling skal i denne sammenhæng altid ses som realisering af et aspekt ved den virkelige verden i form af et program på en computer.
Den ene dimension viser, at systemudvikling finder sted dels i brugerens domæne og dels i computerens domæne. Computerens domæne kunne vi også kalde for eksperternes domæne. De to domæner afspejler de to vigtigste parter, der mødes i systemudviklingsprocessen: brugerne og computereksperterne.
Den anden dimension viser, at systemudvikling omfatter både konkrete og abstrakte aspekter; men det er værd at bemærke, at både udgangspunkt og mål befinder sig i den konkrete del. Udgangspunktet er et problem i den virkelige verden, som man mener vil kunne løses ved hjælp af et computerprogram. Undervejs er systemudvikleren nødt til at fremstille forskellige abstraktioner - bl.a. for at skaffe sig overblik over det problem, der skal løses.
Brugerdeltagelse i systemudviklingen
Som regel vil systemudviklerne komme fra ekspertsiden; men det er for enkelt at sige, at det altid er tilfældet. Der er mange eksempler på, at brugere med de rette værktøjer til rådighed er i stand til at lave systemudvikling.
Under alle omstændigheder er det efter vor mening et vigtigt aspekt i karakteristikken af programudviklingsmiljøet, at man vurderer i hvor høj grad udviklingsmiljøet understøtter brugerdeltagelse i systemudviklingsprocessen.
Brugerdeltagelsen kan være en del af både de reflekterende og realiserende aktiviteter i systemudviklingen; men det må nok indrømmes, at det hyppigst forekommer i de reflekterende aktiviteter. Det hænger efter vor mening sammen med det forhold, at denne del traditionelt ikke er så værktøjstung og derfor ikke kræver så mange forkundskaber hos deltagerne som realiseringen gør. Dette aspekt blev diskuteret i kapitel 1 i forbindelse med gennemgangen af den historiske udvikling af udviklingsmiljøerne.
2.4.2 Traditionel (faseopdelt) systemudvikling
Den traditionelle faseopdelte systemudvikling er kendetegnet ved at der arbejdes systematisk med problemets løsning. Man starter med at lave en analyse af problemet i den virkelige verden. Analysen resulterer i en abstrakt beskrivelse, kravspecifikationen, som tjener flere formål. Et af formålene er, at den tjener som kontraktgrundlag for fastlæggelse af løsningens omfang. Der er derfor en tendens til, at man er meget præcis i sine formuleringer, så man senere undgår tvivl om fortolkningen.
Desværre fører denne præcision til, at man ofte på et meget tidligt tidspunkt i systemudviklingsprocessen føler, at man har mistet en fleksibilitet, som kan være livsvigtig, hvis man skal tilpasse sig ændrede krav og vilkår, der opstår under det fortsatte arbejde med projektet.
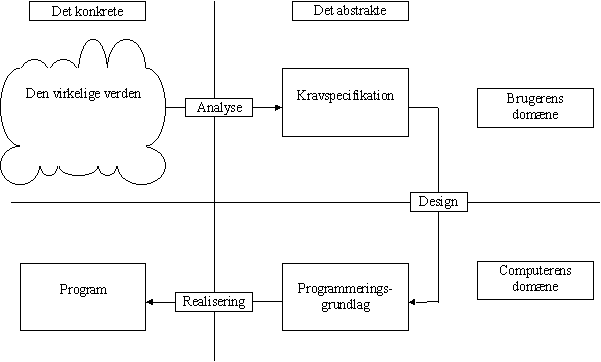
Figur 2-10
. Den traditionelle systemudviklingsproces.Et af de problemer, der som regel nævnes i relation til den traditionelle systemudviklingsproces, er de mange transformationer, som specifikationen undergår frem mod slutproduktet. Disse transformationer udføres af mennesker, og da opgaven ofte er særdeles kompleks, er det nærmest en naturlov, at der vil ske fejl. Den værste transformation er den, der ligger i designaktiviteten, hvor man transformerer fra én abstrakt specifikation til en anden abstrakt specifikation.
Der arbejdes indenfor visse kredse med forsøg på at lave formelle specifikationer. Fordelen ved formelle specifikationer er, at der kan laves programmer, der kan foretage de efterfølgende transformationer automatisk. Herved kunne man eliminere den menneskelige faktor; men det er et håbløst forehavende. Faktisk er det mangefold mere kompliceret at opstille en formel specifikation af et problem end en tilsvarende affattet i naturligt sprog.
Tilhængerne af de formelle specifikationer håber, at der en dag vil komme programmer, der kan transformere naturligt sprog til en formel specifikation; men her overser de den kendsgerning, at der er matematikere, der har bevist, at problemer af denne art har en kompleksitet, der nærmer sig n!. Det ligger uden for rammerne af dette speciale at komme nærmere ind på dette emne.
Realiseringen i den traditionelle systemudvikling rummer ikke større udfordringer end de, der udspringer af programudviklingsmiljøet og det anvendte programmeringssprog; men disse udfordringer kan i mange tilfælde også være store nok.
2.4.3 Objektorienteret systemudvikling
En af fordele ved objektorienteret systemudvikling siges at være, at man slipper for de evindelige transformationer af specifikationer. Det skyldes, at man anvender objektklassen som den grundlæggende abstraktion igennem hele processen. Faktisk kan man i det færdige program genfinde objekter, som er instanser af de samme objektklasser, som man i starten af processen nåede frem til som resultat af analyseaktiviteten.
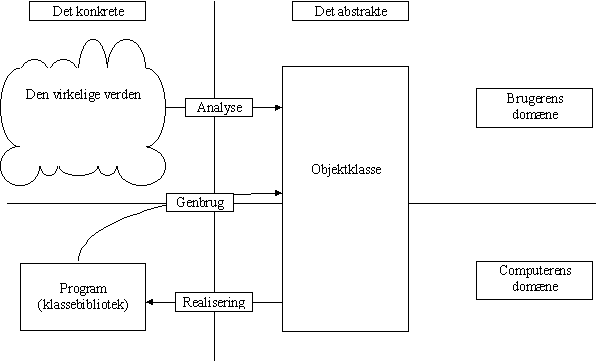
Figur 2-11
. Den objektorienterede systemudviklingsproces.Som det fremgår af figur 2-11 understøtter den objektorienterede systemudvikling især ideen om genbrug. Det kommer til udtryk på den måde, at de objektklasser, der realiseres tidligt i processen inspirerer det fremtidige arbejde i de reflekterende aktiviteter. Dette kan naturligvis kun forekomme i en systemudviklingsproces, der er kendetegnet ved en eksperimenterende, inkremental og iterativ arbejdsform.
Det er naturligvis ingen naturlov, at objektorienteret systemudvikling skal være baseret på en eksperimenterende arbejdsform; men det er dog denne arbejdsform, der anbefales af hovedparten af dem, der har beskrevet den objektorienterede systemudviklingsproces. Blandt disse har vi først og fremmest ladet os inspirere af Grady Booch [Booch91] og Bjarne Stroustrup [Stroustrup91].
Ideen med at lade tidligere udviklede klasser i klassebiblioteket virke som inspiration i det fortsatte arbejde er bl.a. beskrevet i en artikel af Jean Marc Nerson [Nerson92].
Realiseringen i det objektorienterede programudviklingsmiljø følger et andet mønster end det, man så i den traditionelle systemudvikling.
Dette afsnit indeholder en opsummering af vores delvis selvkomponerede taksonomi. Vi medtager først kriterier for de forskellige elementer, som vi gennemgik i de foreående afsnit og opregner hvilke systemudviklingsmæssige principper, der understøttes.
I forbindelse med værktøjerne har vi valgt at se bort fra debugger, job kontrol sprog og CASE værktøj, fordi vi har bestemt os for, at ingen af disse tre kriterier skal kunne spille en afgørende rolle for bedømmelsen af et udviklingsmiljøs kvalitet.
I afsnittet om editorer (2.2.1) kom vi frem til, at der kan identificeres fire typer af editorer:
Hvilken type editor, der er den bedste, vil afhænge af de opgaver, man har tænkt sig at løse med den.
2.5.2 Oversætter, fortolker og linker
I afsnittet om oversætter, fortolker og linker (2.2.2) kom vi frem til, at man skelner mellem oversættere og fortolkere:
Oversætterens eller fortolkerens kvalitet afhænger især af fejlmeddelelsernes kvalitet, oversætterens udførselshastighed samt størrelse og afviklingshastighed for det færdige program. Det typiske billede er, at oversættere er længere tid om at oversætte; men til gengæld er det færdige program effektivt. I modsætning hertil er fortolkere typisk hurtige til oversættelsen; men til gengæld langsomme under udførelse af det færdige program.
Om man i en given situation foretrækker oversætter eller fortolker afhænger af karakteren af den opgave, der skal løses.
En vigtig facilitet ved oversætteren er, om den giver mulighed for at lave kald til makroer. Denne mulighed er vigtig, fordi den tillader genbrug af meget brugte kodesekvenser. Hermed opnår man en stor ensartethed i opbygningen af programmerne.
En tilsvarende vigtig facilitet ved linkeren er, om den tillader inkremental udvikling af programmer, således at programmer kan udvikles i moduler, som så senere samles til eksekverbare helheder.
I afsnittet om integration (2.3.1) identificeredes en række kriterier, der har betydning for bedømmelsen af udviklingsmiljøet:
I afsnittet om inkrementalitet (2.3.2) identificeredes et kriterium, der har betydning for bedømmelsen af udviklingsmiljøet:
og vi besluttede os for at se på i hvilket omfang produktet understøtter en eller flere af følgende:
I afsnittet om interaktivitet (2.3.3) identificeredes et kriterium, der har betydning for bedømmelsen af udviklingsmiljøet:
I afsnittet om systemudviklingsprocessen (2.4) identificeredes følgende kriterier, der har betydning for bedømmelsen af udviklingsmiljøet:
I dette afsnit vil vi resumere den taksonomi, vi vil pege på som anvendelig i forhold til programudviklingsmiljøer. Som nævnt er det vores arbejdshypotese, at taksonomien vil vise sig at være utilstrækkelig til bedømmelse af visuelle programudviklingsmiljøer.
|
|
Kriterium
|
Svarmuligheder |
|
Editor |
Type |
Generel, tekst-orienteret, struktur-orienteret eller syntaks-dirigeret |
|
Compilersystem |
Type |
Oversætter eller fortolker |
|
|
Mulighed for makroer |
Ja / nej |
|
Linker |
Inkremental programudvikling |
Ja / nej |
|
Integration |
Antal repræsentationer |
Få / middel / mange |
|
|
Ensartede værktøjer |
Ja / nej |
|
|
Graden |
Fritstående / integrerede værktøjer |
|
Inkrementalitet |
Graden |
Høj / middel / lav |
|
|
Programming-in-the |
Small/many/large (flere mulige) |
|
Interaktivitet |
Graden |
Høj / middel / lav |
|
Systemudvikling |
Grundfilosofi |
Top-down / bottom-up eller objektorienteret |
|
|
Arbejdsform |
Planlagt / eksperimentel |
|
|
Graden af brugerdeltagelse |
Høj / middel / lav |
Tabel 2-1.
Oversigt over en taksonomi til bedømmelse og sammenligning af programudviklingsmiljøer.